滴水逆向--01-27 C语言03_数据类型_IF语句
课后作业
做的是有基础的那部分
-
有一个字符串是这样的:
china中国verygood天朝nice,里面既含有中文又含有英文,请编写一个函数,能截取任意长度的字符串 n(n<=总长度)1
2
3fn(5) = china
fn(6) = china中
fn(8) = china中国v此题涉及到字符存储所占字节大小的问题,英文字符占一字节,课上讲的中文字符是占二字节(GB2312)。但是我写这个题目的时候是在家里,手头只有一个平时用的mac,做逆向用的那个win本搁学校里没有带回来,所以就没法用这个老旧windows环境下的GBK,只能用现代默认的UTF-8编码了,原理上都是大差不离的。
首先先来看看 UTF-8 的编码规则(x 表示可用编码位):
字节数 能表示什么字符 编码长什么样 每个字节的大概范围 1 字节 最普通的英文、数字、符号,比如 A、1、,0xxxxxxx0x00到0x7F2 字节 一些扩展字符,比如带音标的欧洲字符、中东字符等 110xxxxx 10xxxxxx首字节范围: 0xC2到0xDF;后面字节:0x80到0xBF3 字节 绝大多数常见汉字,比如 你、中、文1110xxxx 10xxxxxx 10xxxxxx首字节范围: 0xE0到0xEF;后面字节:0x80到0xBF4 字节 emoji、很生僻的汉字、一些特殊符号,比如 😀11110xxx 10xxxxxx 10xxxxxx 10xxxxxx首字节范围: 0xF0到0xF4;后面字节:0x80到0xBF简单来讲,如果一个字节的第一位是 0,则这个字节单独就是一个字符;如果第一位是 1,则连续有多少个 1,就表示当前字符占用多少个字节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
void substr(char *src, int n, char *dest) {
int idx = 0; // 记录当前扫描到的字节位置
int cnt = 0; // 记录当前已经扫描的逻辑字符个数
while (src[idx] != '\0' && cnt < n) {
unsigned char c = src[idx];
// 根据UTF-8的首字节规则,判断跳过几个字节
if ((c & 0x80) == 0x00) {
idx += 1; // 1字节
} else if ((c & 0xE0) == 0xC0) {
idx += 2; // 2字节
} else if ((c & 0xF0) == 0xE0) {
idx += 3; // 3字节
} else {
idx += 4; // 4字节
}
cnt++;
}
strncpy(dest, src, idx);
dest[idx] = '\0';
}
int main() {
char *s = "china中国verygood天朝nice";
char ans[100];
int num;
while (scanf("%d", &num)) {
substr(s, num, ans);
printf("fn(%d) = %s\n", num, ans);
}
return 0;
}运行效果:

-
指针可以做乘法运算吗?如何实现?
在标准C语言中,由于指针代表的是内存地址,它可以进行加减操作,你对指针去加或者减上一个数,可以表示在内存中向前/向后移动。但是乘除操作是无意义的,直接使用编译器会报错
不过在计算机的眼里,指针本质上就是一个地址,而地址在机器里就是一个整数。所以可以通过强制类型转换来实现指针的乘法运算,先把指针转换为整数,运算过后再还原回去。GPT 大人说这里可以用 uintptr_t 类型,这是一种专门用来保存指针地址的无符号整数类型,它的长度永远和当前系统的指针长度一样,不用担心精度问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
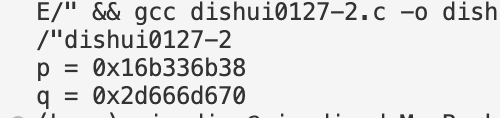
int main() {
int a = 10;
int *p = &a;
uintptr_t addr = (uintptr_t)p;
uintptr_t new_addr = addr * 2;
int *q = (int *)new_addr;
printf("p = %p\n", p);
printf("q = %p\n", q);
return 0;
}运行结果: