滴水逆向--02-02 参数_返回值_局部变量_数组反汇编
返回值的传递
char类型的返回值:用al存short类型的返回值:用ax存int类型的返回值:用eax存- 宽度为 64 位的返回值数据类型要怎么存储?见作业1
参数传递
- 本机尺寸:如果本机是 32 位的,那么对 32 位的数据支持最好,如果是 64 位的,那么对 64 位的支持最好。编译器也遵守了这个规则:char 类型或者 short 类型的参数不但没有节省空间,反而浪费了多余的操作(比如会进行符号拓展)。
所以很多人误以为使用 char 或 short 类型总能节省内存,但在底层传递和存储时,你定义的虽然是一个/两个字节,但是编译器会统一按照 32 位四字节去传递,而且现代 64 位编译器也都是优先使用寄存器传参了,所以对于函数参数和局部变量来说,去定义一个小一点的数据类型没什么鸟用。不过对于结构体和数组,这时候用 char 和 short 就有意义了,因为在内存中连续大批量存储时,编译器会进行打包,这时候千万个 char 就能省下大量内存。 - 参数传递的本质:将上层函数的变量,或者表达式的值“复制一份”,传递给下层函数
局部变量的内存分配
局部变量会影响编译器在函数调用初始化时的缓冲区空间,函数提升堆栈时,开辟的缓冲区大小默认为 0x40(并不绝对,不同编译器不一样),如果函数中定义了一个局部变量,大小也会相应增加,每个局部变量增加 4 字节,不管类型是什么
总结:
- 小于32位的局部变量,空间在分配时,按32位分配
- 使用时按实际的宽度使用
- 不要定义char/short类型的局部变量,直接上 int
- 参数与局部变量没有本质区别,区别只是参数是在函数调用时分配的,局部变量是在函数执行时分配的,本质上 都是局部变量,都在栈中分配
- 完全可以把参数当初局部变量使用
数组
数组的本质就是一排等宽的数据
数组的堆栈分配:
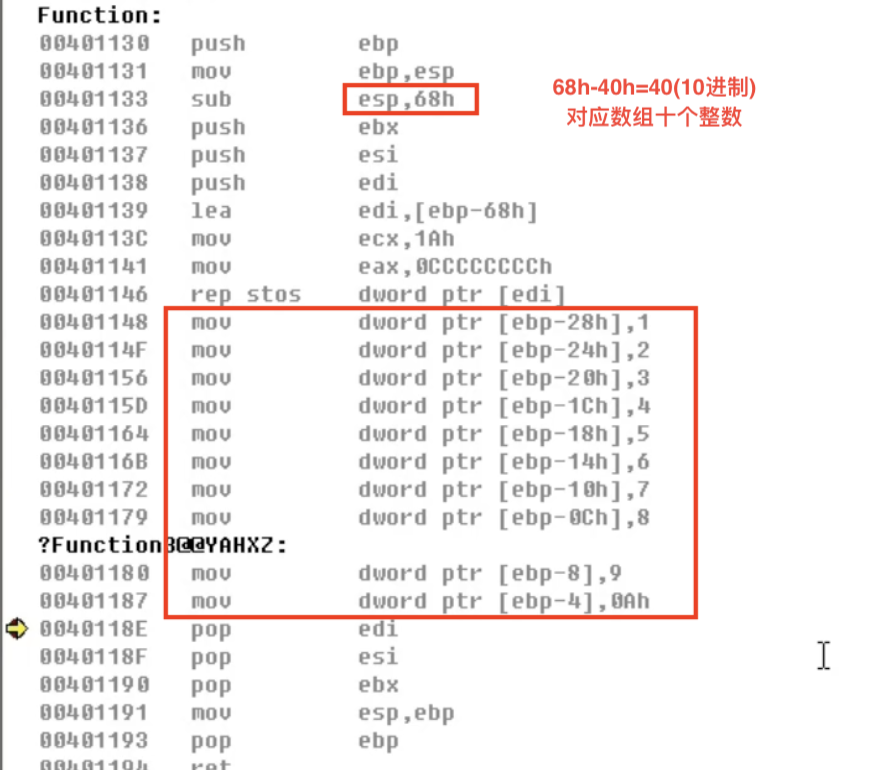
课后作业
-
返回值超过32位时,存在哪里?用long long(__int64)类型做实验
1
2
3
4__int64 Func(){
__int64 x = 0x1234567890;
return x;
}汇编代码如下:
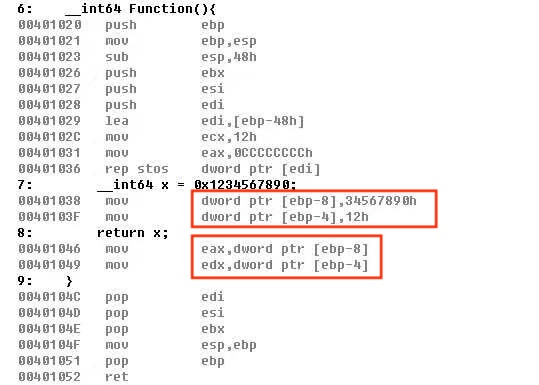
存储时先对 0x1234567890 进行补齐,在前面补 0,变成 0x 00000012 34567890。低 32 位(34567890h)存入低地址 [ebp-8],高 32 位(00000012h)存入高地址 [ebp-4]。
正常来讲,函数返回值是通过 eax 寄存器带回的,但是 64 位的要怎么带呢,从汇编中可以看出它是拉上了 edx 寄存器一起干活,eax 存低位,edx 存高位,两个寄存器共同拼成一个 64 位的数据 -
char arr[3] = {1,2,3};与char arr[4] = {1,2,3,4};哪个更节省空间,从反汇编的角度来说明你的观点char arr[4] = {1,2,3,4};更省,由于编译器需要对齐,所以两个实际上都 4 字节的内存,但是 arr[3] 会造成空间的浪费。不过这也不能说省吧,毕竟俩都是一样的,只能说利用率更高。将此疑惑问过ai后,它说如果开启了编译器优化,arr[4] 会被编译器拼成一个完整的 32 位整数(如 0x04030201),只需 1 条指令(mov dword)就能完成赋值,机器码体积小,而 arr[3] 凑不齐标准字长,就会被迫拆分成 2~3 条碎片化指令写入,这样就会增加编译后的程序体积,所以 arr[4] 要更优。 -
找出下面赋值过程的反汇编代码
1
2
3
4
5
6
7
8
9
10
11void Function() {
int x = 1;
int y = 2;
int r;
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
r = arr[1];
r = arr[x];
r = arr[x+y];
r = arr[x*2+y];
}
-
桶排序
课上讲的严格来说应该是计数排序,懒得做了,两个都可以在 oiwiki 上看
得去搞期末考试了,可能会断更近一个月